Data standards — Papers Past newspaper open data
Information about the data standards we use for the Papers Past newspaper open data.
Papers Past data standards
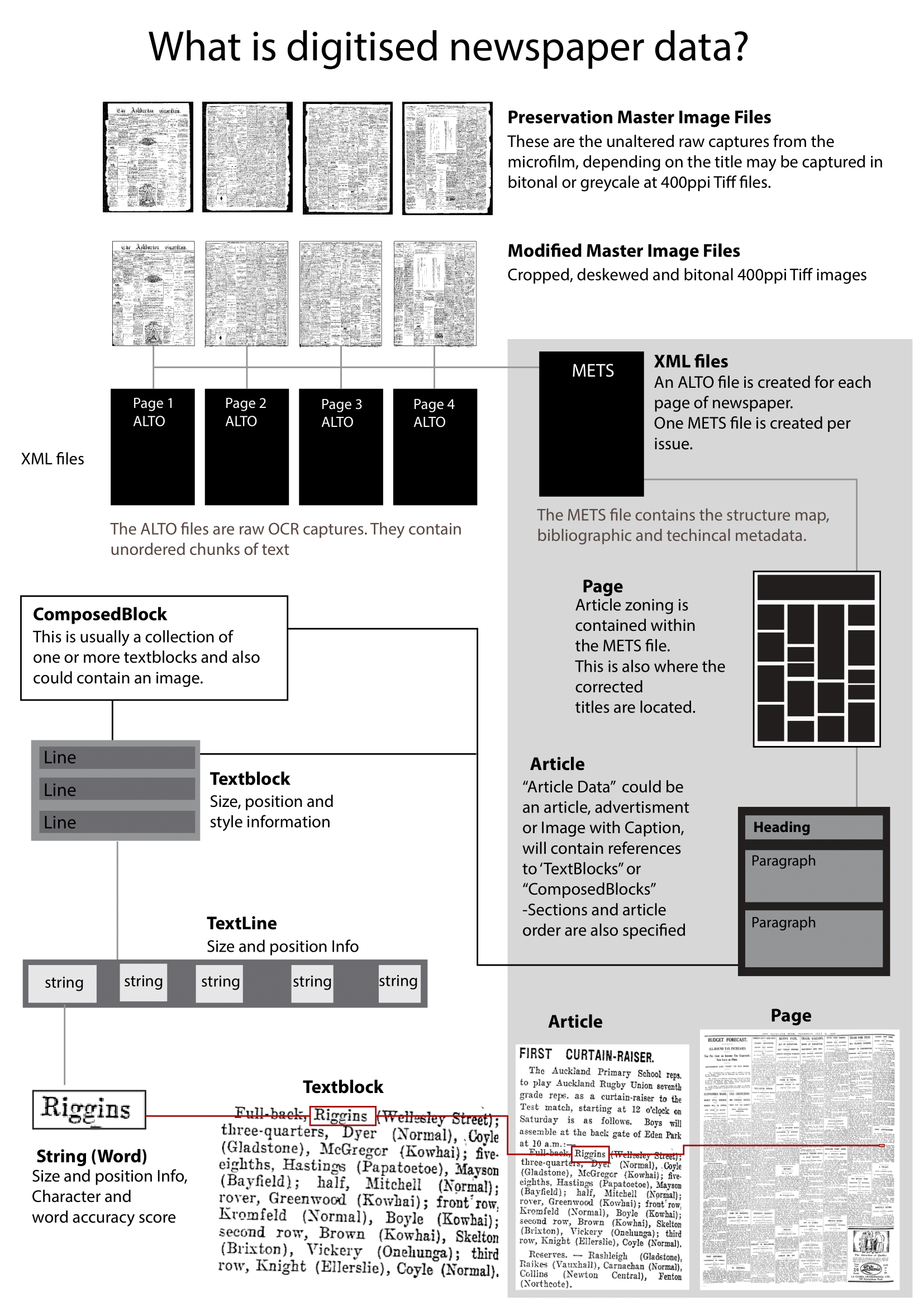
The Papers Past Newspapers data consists of METS/ALTO XML files from 108 historic New Zealand newspapers published more than 120 years ago. Each year more data will be released. The data doesn’t contain the page images of the newspapers.
METS (Metadata Encoding and Transmission Standard) is a Library of Congress standard used to describe digital objects. This includes bibliographic, administrative and structural information about the digitised material, as well as a list of files.
ALTO is a Library of Congress standard for storing layout information, font information and OCR (Optical Character Recognition) text.
Veridian software — What is METS/ALTO? this is a good introduction to METS/ALTO by the people who make the software that powers Papers Past.
How the Papers Past data is created
Newspapers are normally digitised for Papers Past from microfilm. This means that the images you see on the website are third-generation images — that is they are created from a copy of the film image of the original newspaper page. The film is scanned, then cropped and de-skewed as necessary, and saved as two separate Tiff files:
Preservation Master — the raw capture straight from the scanner, and
Modified Master — the cropped and de-skewed version, which is then put through an automated image conversion process.
Each page has an ALTO file created during image conversion, using Optical Character Recognition (OCR) technology to capture the text. The image conversion process creates blocks of text with coordinates, accuracy, and font information.
Each issue of a newspaper has one METS file. The METS file acts as a guide to the ALTO files and page images. It contains the corrected headlines and text blocks organised into reading order.
As the METS/ALTO data is created by an automated process, it is not always 100% accurate. It is not manually corrected after creation except in the case of headlines.
The METS/ALTO files are used to generate the indexes and link to the images you see on Papers Past
Digitised newspaper technical makeup.
Structure of the data
Be wary about moving individual XML files around as they are not uniquely named.
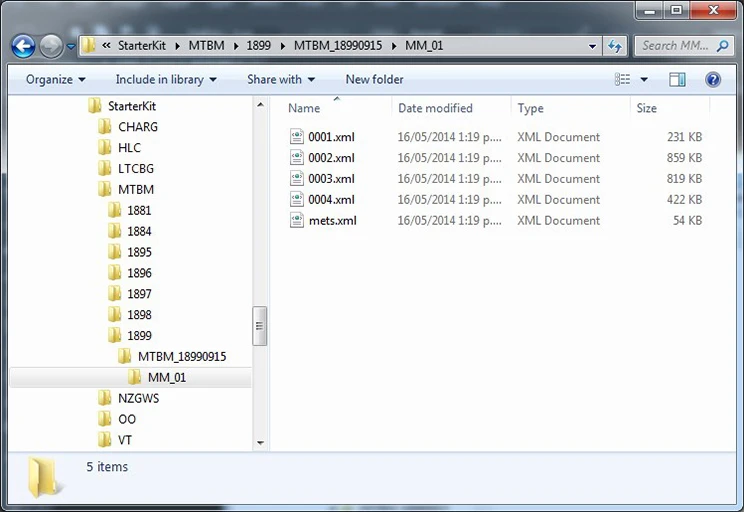
In the example below, you can see the directory structure that the data has been provided in.
Example of an open data directory structure.
Each newspaper title has a folder named with an acronym. In the example above the acronym, MTBM stands for the Mt Benger Mail.
For every newspaper title, there is one folder for each year.
Within the year, each issue has a separate folder.
These are named in the following format “ACRO_yyyymmdd” — where ACRO is the title acronym, yyyy is the year of publication, and mmdd is the month and day the issue was published.
For every issue, there is a folder for the modified masters (MM_01). The METS and ALTO files sit within the MM_01 folder.
The METs and ALTO file names are the same across all titles and issues — such as mets.xml, 0001.xml, 0002.xml etc. It is only the directory structure that is individualised.
As well as the XML formats, bibliographic metadata has been provided at the title level as a MARC record and as a Readme file in YAML format.
MARC stands for Machine-Readable Cataloging. It is a Library of Congress standard that describes library collections.
YAML stands for YAML Ain't Markup Language. YAML is a human-readable, structured, data format. Usually used in configuration files, here it has been used to embed structured metadata into each Readme file in a format that is easily readable by both humans and machines.
Get in touch
Let us know how you've found using the data, what's gone well, what hasn't worked, or what might make things easier.
If you have any questions about the data or would like to let us know about projects you have been working on with it, please get in touch.
Email us — paperspast@natlib.govt.nz
Related content

Dataset — Papers Past newspaper open data
Download individual newspaper titles or get all the Papers Past open data. Each year of data includes mets.xml and page-level alto.xml for each issue published that year. It does not include images.
Copyright and re-use — Papers Past newspaper open data
Information about copyright and re-use of the data in the Papers Past open dataset.Feature image at top of page: Image created by Greig Roulston from pictures from the pilot dataset.